今日从 arXiv 订阅中筛选 8 篇论文。
⚡ ST-Prune Training-Free Spatio-Temporal Token Pruning for Vision-Language Models in Autonomous Driving
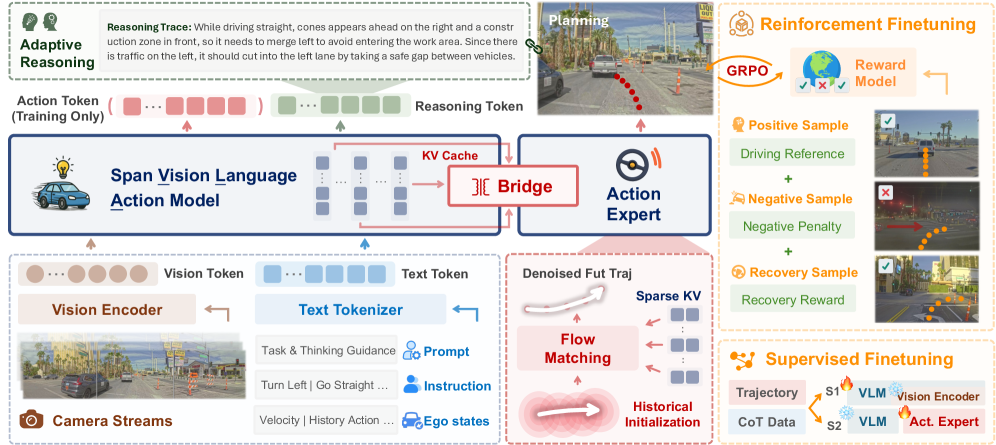
⚡ SpanVLA Efficient Action Bridging and Learning from Negative-Recovery Samples for Vision-Language-Action Model
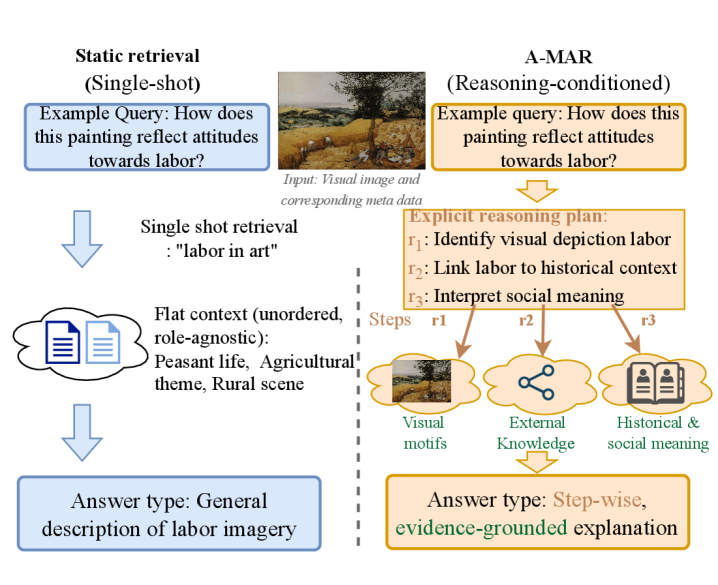
⚡ A-MAR Agent-based Multimodal Art Retrieval for Fine-Grained Artwork Understanding
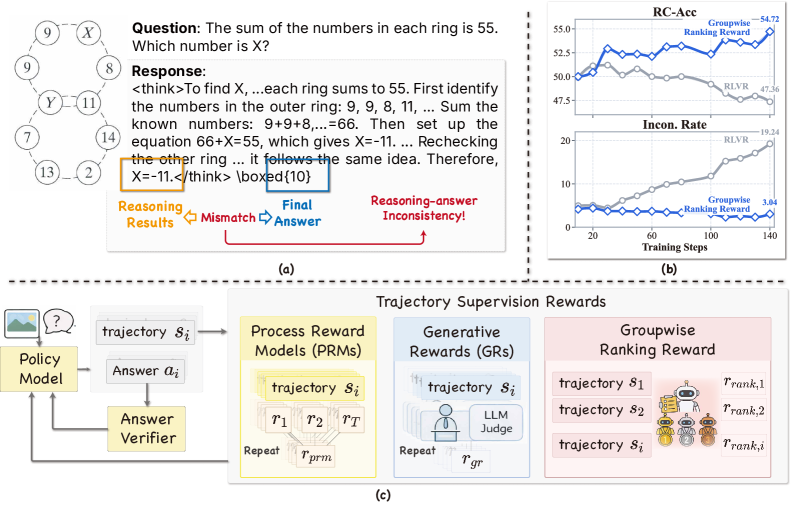
⚡ Prioritizing the Best Incentivizing Reliable Multimodal Reasoning by Rewarding Beyond Answer Correctness
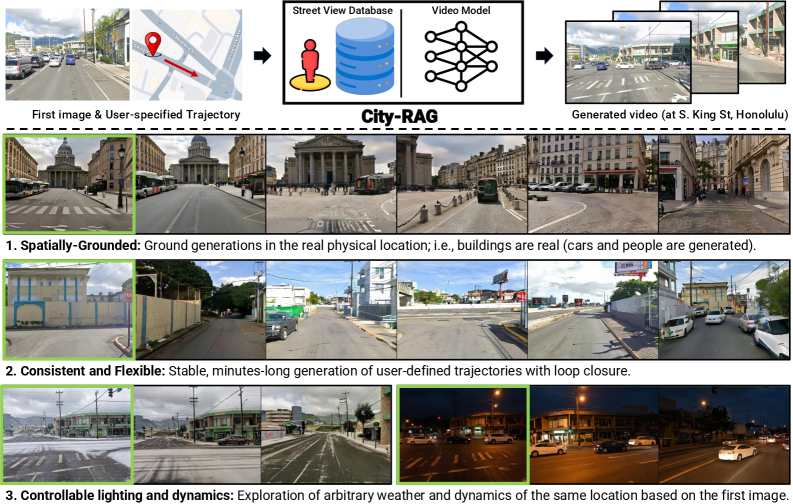
⚡ CityRAG Stepping Into a City via Spatially-Grounded Video Generation
⚡ EgoMotion Hierarchical Reasoning and Diffusion for Egocentric Vision-Language Motion Generation

⚡ Explore Like Humans Autonomous Exploration with Online SG-Memo Construction for Embodied Agents
自动生成于 2026-04-22 · 基于 arXiv Daily Digest