今日从 arXiv 订阅中筛选 9 篇论文。
⚡ Learning to Theorize the World from Observation
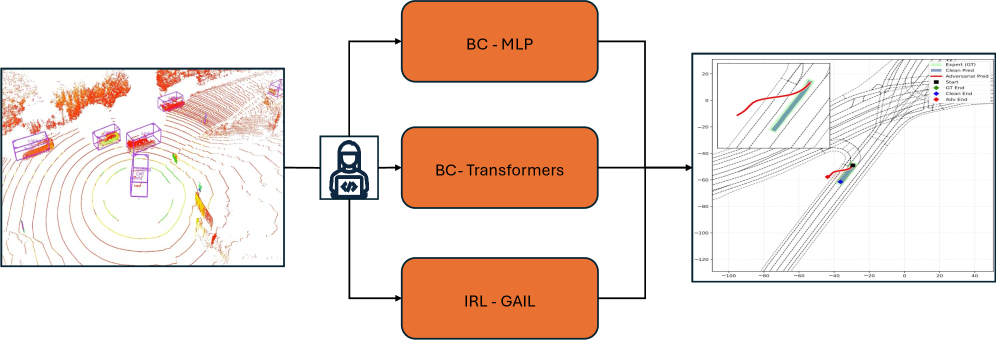
用真实路口数据做自动驾驶轨迹学习的 adversarial robustness 评估,比较 BC-MLP/BC-Transformer/GAIL-IRL 三种范式在 PGD 攻击下的表现,直接命中 collision/hazard/trajectory 主线。
⚡ Reasoning-Guided Grounding: Elevating Video Anomaly Detection through Multimodal Large Language Models (VANGUARD)
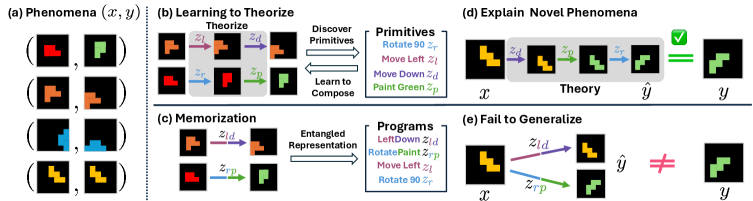
从 developmental cognitive science 的 "theory-building" 视角出发,提出 Neural Theorizer (NEO),用 latent programs 作为可执行的 compositional world theory,而非 latent-spa
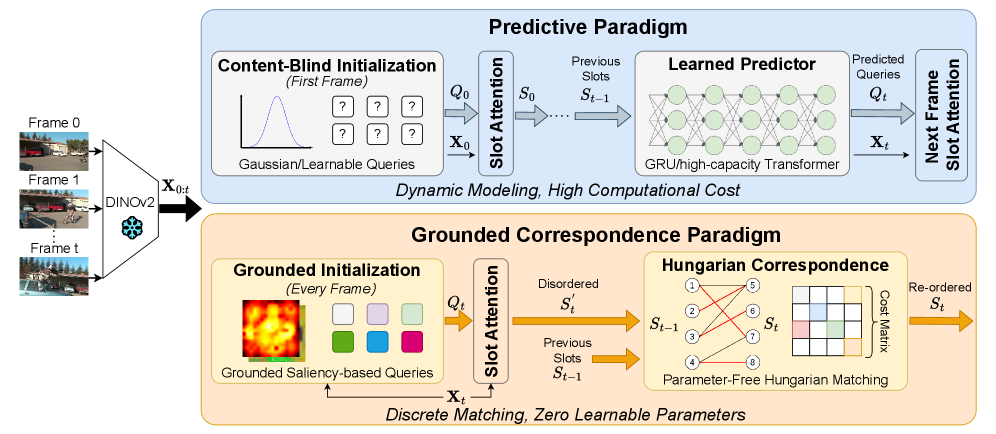
⚡ Rethinking Temporal Consistency in Video Object-Centric Learning: From Prediction to Correspondence
首次在 VLM 框架内统一 anomaly classification + spatial grounding + chain-of-thought reasoning,三阶段课程训练,在 UCF-Crime 上达到 94% AUC,同时输出可解释推理和异常目标定位,直接覆盖 reasoning

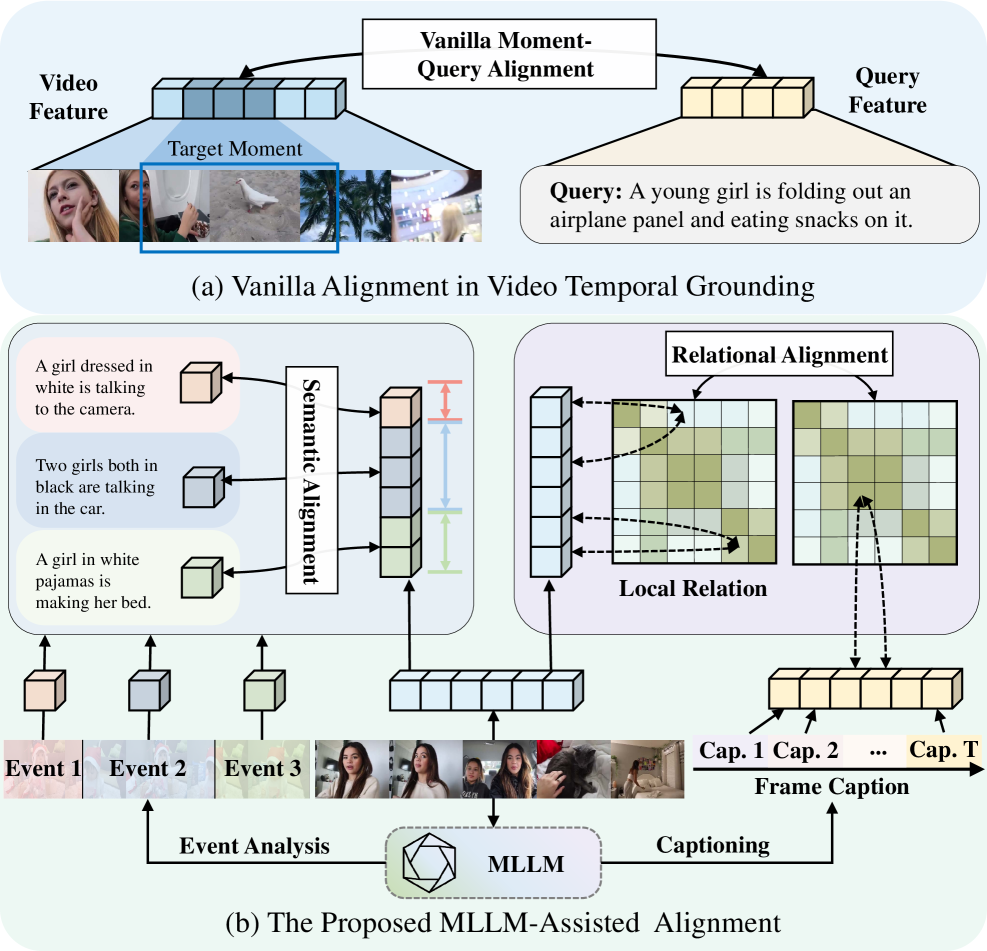
⚡ MASRA: MLLM-Assisted Semantic-Relational Consistent Alignment for Video Temporal Grounding
放弃 learned dynamics predictor,改用 frozen DINOv2 backbone + Hungarian bipartite matching 做 slot correspondence,零可学习参数实现 temporal consistency,object-cent
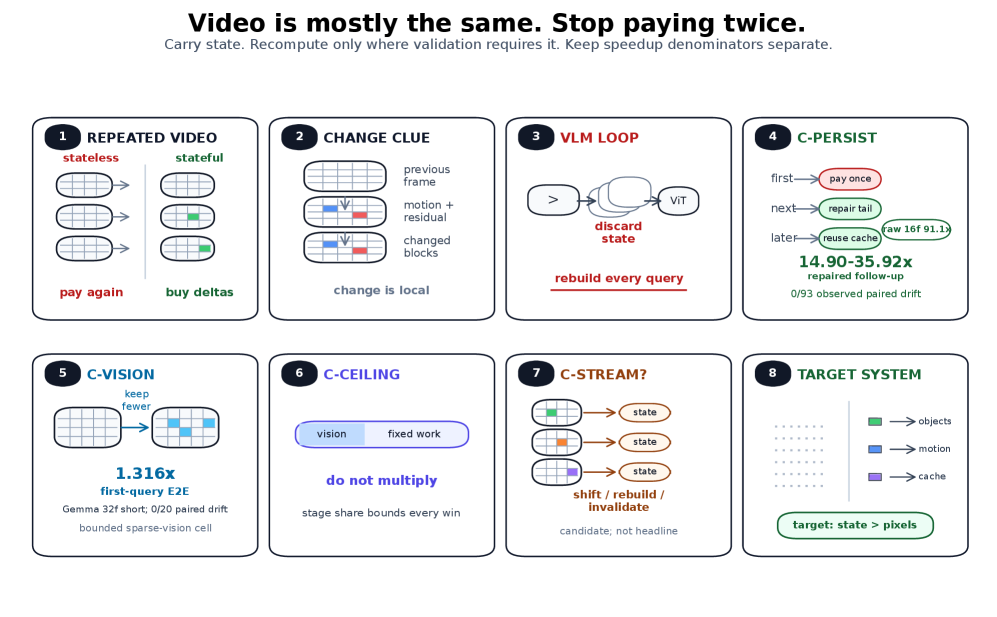
⚡ VLMaxxing through FrameMogging: Training-Free Anti-Recomputation for Video Vision-Language Models
用 MLLM 生成 event-level description 和 clip-level caption 作为训练辅助信号,做 video temporal grounding 的语义-关系一致性对齐,training-time 使用 MLLM、inference 无额外开销,video und
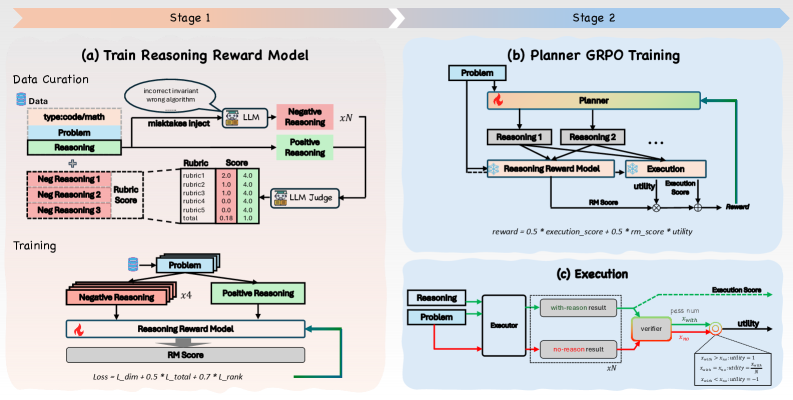
⚡ Correct Is Not Enough: Training Reasoning Planners with Executor-Grounded Rewards (TraceLift)
training-free 的 video VLM 推理加速:通过验证视觉状态是否变化来决定复用还是重新计算,follow-up query 加速 15-36x,方法工程味重但思路直接有用,适合做 video understanding 系统参考。
⚡ Say the Mission, Execute the Swarm: Agent-Enhanced LLM Reasoning in the Web-of-Drones
提出 executor-grounded reward 训练 reasoning planner——不仅看最终答案是否正确,更看推理 trace 对 executor 的实际 uplift,构建 TraceLift-Groups 含高质量/扰动后 trace 对比,reasoning + RL +
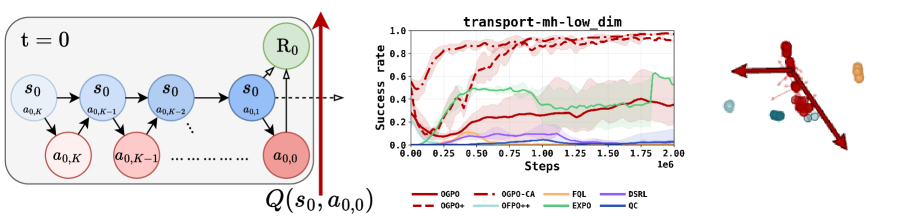
⚡ OGPO: Sample Efficient Full-Finetuning of Generative Control Policies
LLM agent + UAV swarm 的 closed-loop 控制系统,用 W3C WoT 标准做 grounding,支持持续状态观测和自主推理,6 个 LLM 在 4 个 swarm 任务上评估,agent + closed-loop。

⚡ Intro
用 off-policy critic + PPO-style gradient 对 diffusion/flow 生成式控制策略做 sample-efficient finetuning,在 Robomimic 和 Franka Kitchen 上大幅超越 behavior cloning,RL
自动生成于 2026-05-06 · 基于 arXiv Daily Digest