今日从 arXiv 订阅中筛选 10 篇论文。
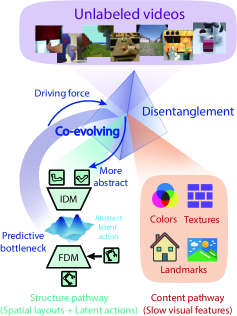
⚡ DiLA: Disentangled Latent Action World Models
内容-结构解耦潜在动作世界模型,解决动作抽象与生成保真度矛盾。无标签自监督,支持跨体现动作迁移。
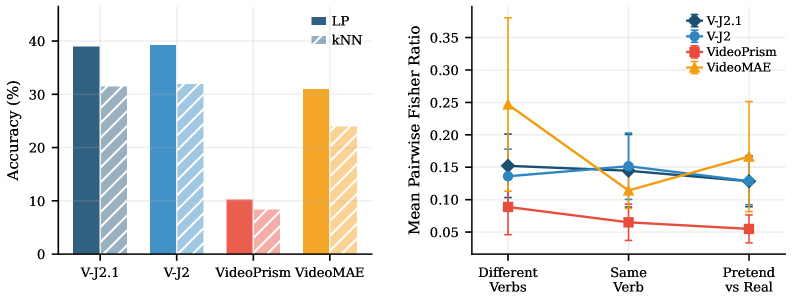
⚡ Latent Video Prediction Learns Better World Models
首次系统评估四种视频基础模型五维度鲁棒性。潜在预测模型V-JEPA在所有维度一致优于像素重建/对比方法。
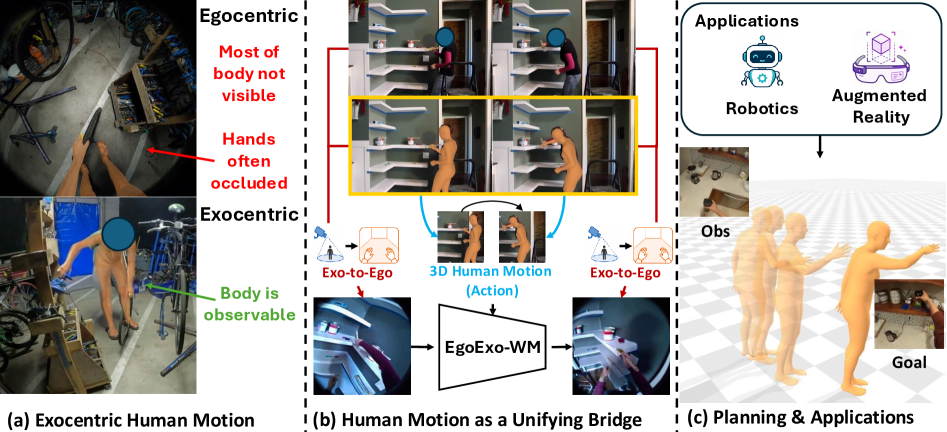
⚡ EgoExo-WM: Unlocking Exo Video for Ego World Models
利用外部视角视频增强自我中心世界模型,解决ego数据稀缺与域间差距。
⚡ Entity-Centric World Models: Interaction-Aware Masking for Causal Video Prediction
交互感知掩码因果视频预测世界模型,以实体为中心建模交互关系。
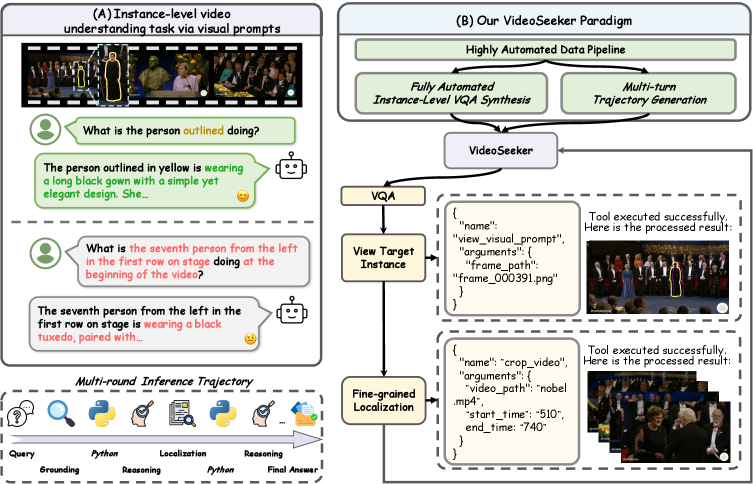
⚡ VideoSeeker: Incentivizing Instance-level Video Understanding via Native Agentic Tool Invocation
原生agentic工具调用做实例级视频理解,RL激励工具使用提升细粒度感知。
⚡ Minerva-Ego: Spatiotemporal Hints for Egocentric Video Understanding
自我中心视频推理基准+时空推理轨迹标注。定位提示显著提升模型表现。

⚡ UAM: A Dual-Stream Perspective on Forgetting in VLA Training
双流视角分析VLA训练灾难性遗忘,揭示视觉-语言-动作微调中遗忘模式。
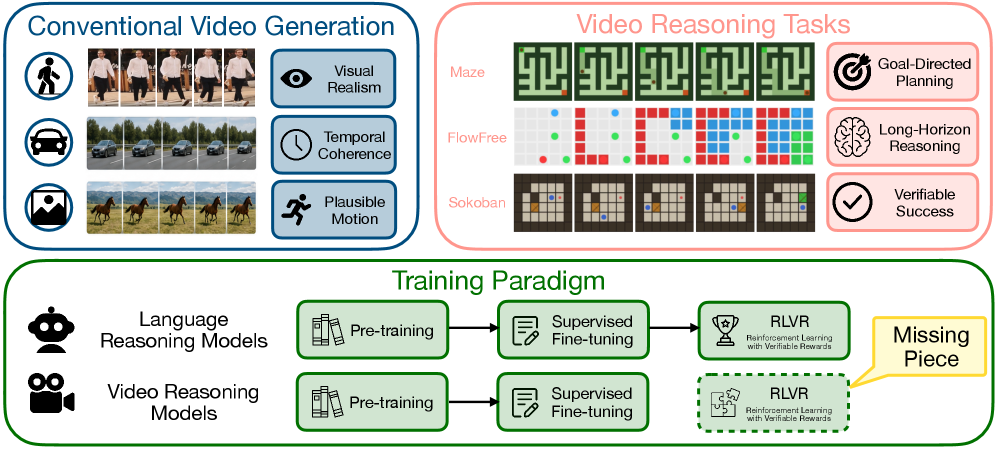
⚡ Video Models Can Reason with Verifiable Rewards
可验证奖励训练视频扩散模型推理,将推理信号注入视频生成过程。
⚡ PanoWorld: Geometry-Consistent Panoramic Video World Modeling
从单图+描述生成几何一致的全景360°视频世界模型。
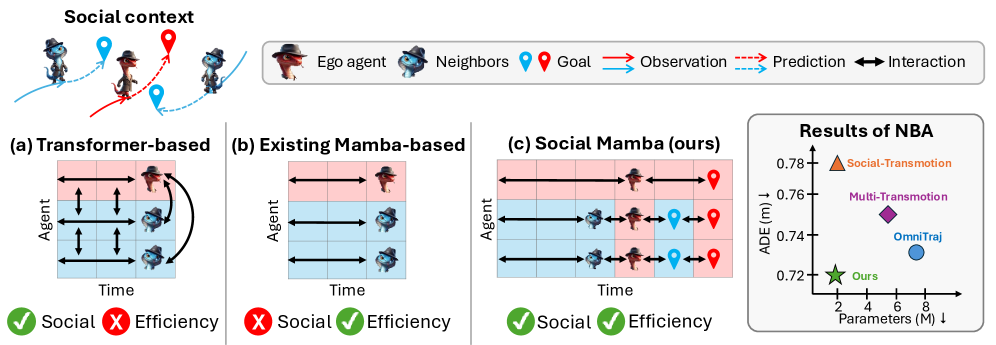
⚡ Social-Mamba: Socially-Aware Trajectory Forecasting with State-Space Models
基于SSM的社交感知轨迹预测,平衡精度与效率。
自动生成于 2026-05-18 · 基于 arXiv Daily Digest