今日从 arXiv 订阅中筛选 10 篇论文。
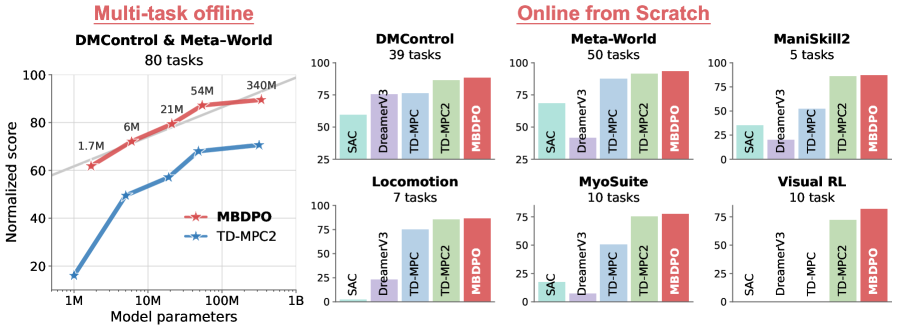
⚡ Scaling World-Model RL Through Diffusion Policy Optimization
用扩散策略优化统一世界模型中的搜索与价值学习,解决模型偏差和错误累积问题。
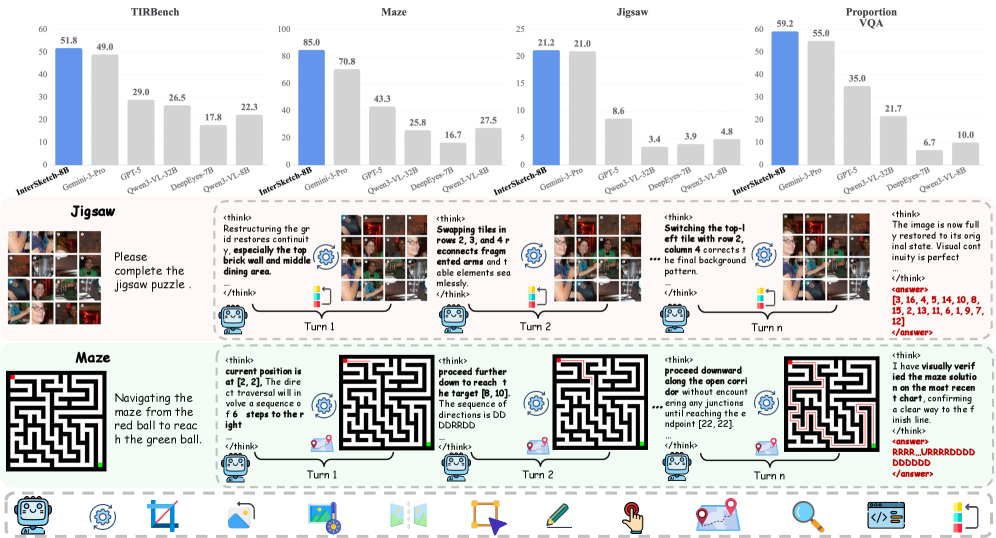
⚡ InterSketch: An Interleaved Reasoning Model with Self-correcting Visual Sketch and Stepwise Reward
交错视觉-文本思维链 (VT-CoT) + 自修正草图,提升 VLM 多轮视觉推理深度。
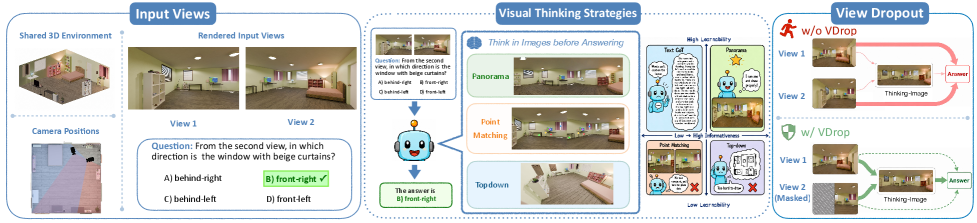
⚡ How and What to Imagine? Visual Thinking in Unified Multimodal Models for Cross-View Spatial Reasoning
揭示 VLM 在跨视角空间推理中"用语言思考而非真正视觉思考"的局限。
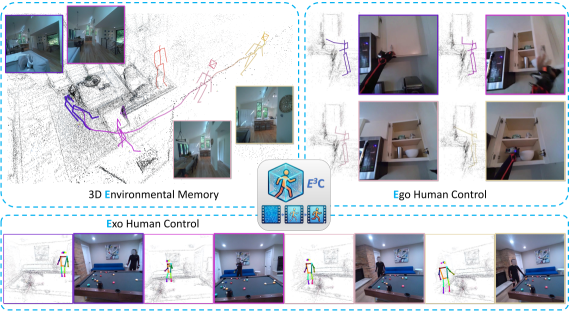
⚡ E3C: Video Generation with 3D Environmental Memory and Ego-Exo Human Pose Control
可控的第一人称视频生成,结合 3D 点云环境记忆与人体姿态控制。
⚡ D Gaussian Map with Open-Set Semantic Grouping for Vision-Language Navigation
3DGS 做 VLN 语义建图,开放集语义分组替代稠密特征采样。
⚡ DynFrame: Adaptive Reasoning-Driven Multimodal Framework with Dynamic Frame Augmentation
自适应帧采样密度作为原生 token,配合 SD-GRPO 实现单步多粒度证据获取。
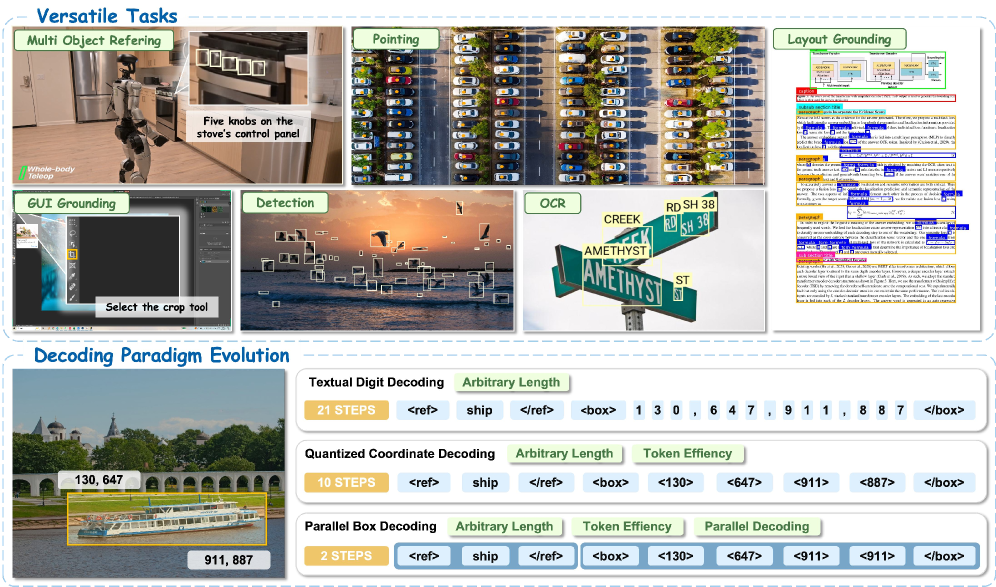
⚡ LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
并行 box 解码替代序列化坐标生成,提升 grounding 吞吐与精度。
⚡ Pop-Up Distractions Reveal Bag-of-Events Behavior in Video Large Language Models
发现 VideoLLM 存在"事件袋"行为:跨段实体关联失败、幻觉交互。
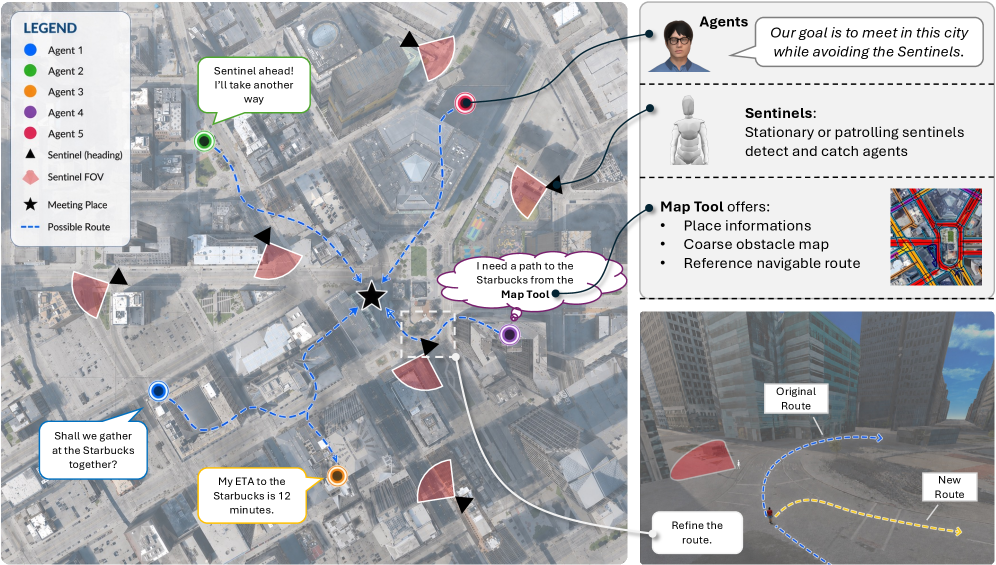
⚡ Sentinel: Embodied Cooperative Spatial Reasoning and Planning
去中心化具身智能体在城市场景中的协同空间推理与重新规划。
⚡ Adaptation-Free Heterogeneous Collaborative Perception with Unseen Agent Configurations
零适配异构协同感知,box 级消息转 ego 兼容特征,仅需 120 字节/帧。
自动生成于 2026-05-27 · 基于 arXiv Daily Digest