今日从 arXiv 订阅中筛选 10 篇论文。
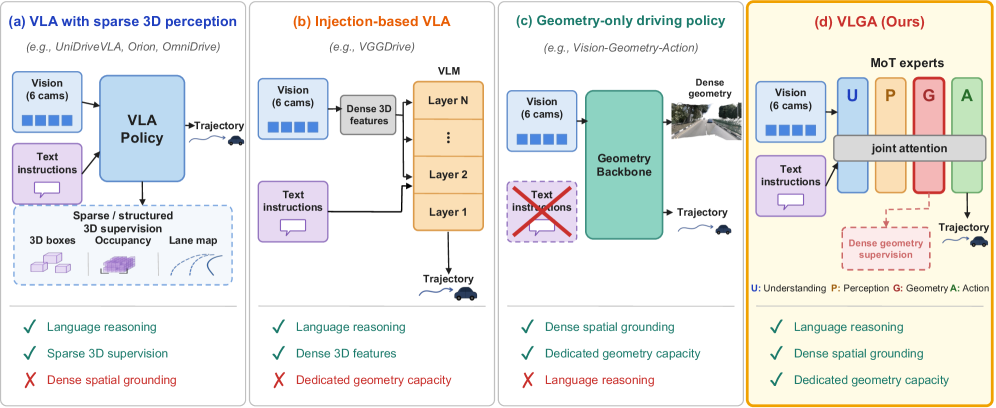
⚡ VLGA: Vision-Language-Geometry-Action Models for Autonomous Driving
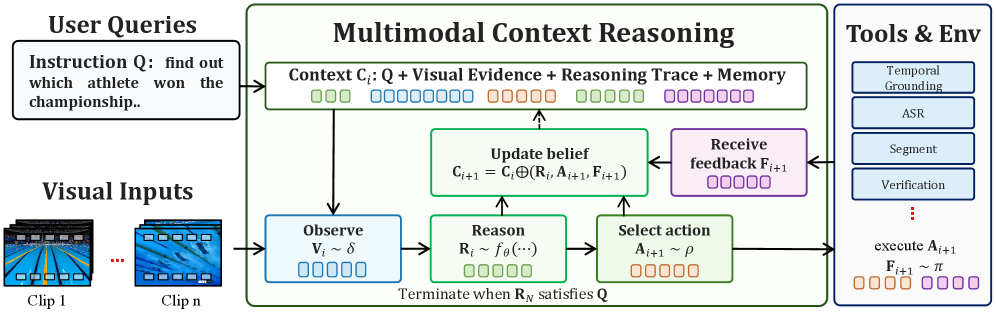
⚡ InternVideo3: Agentify Foundation Models with Multimodal Contextual Reasoning
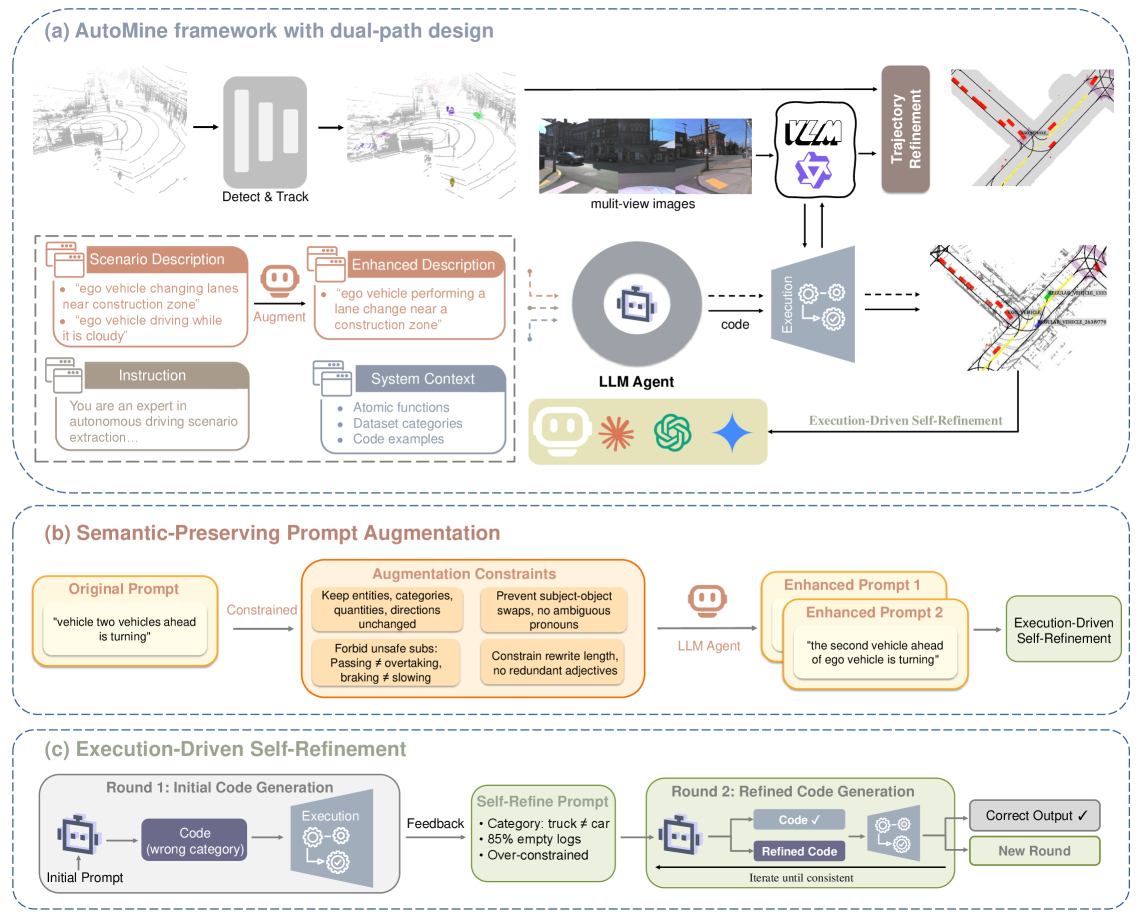
⚡ Task-Aligned Stability Analysis of Vision-Language Models for Autonomous Driving
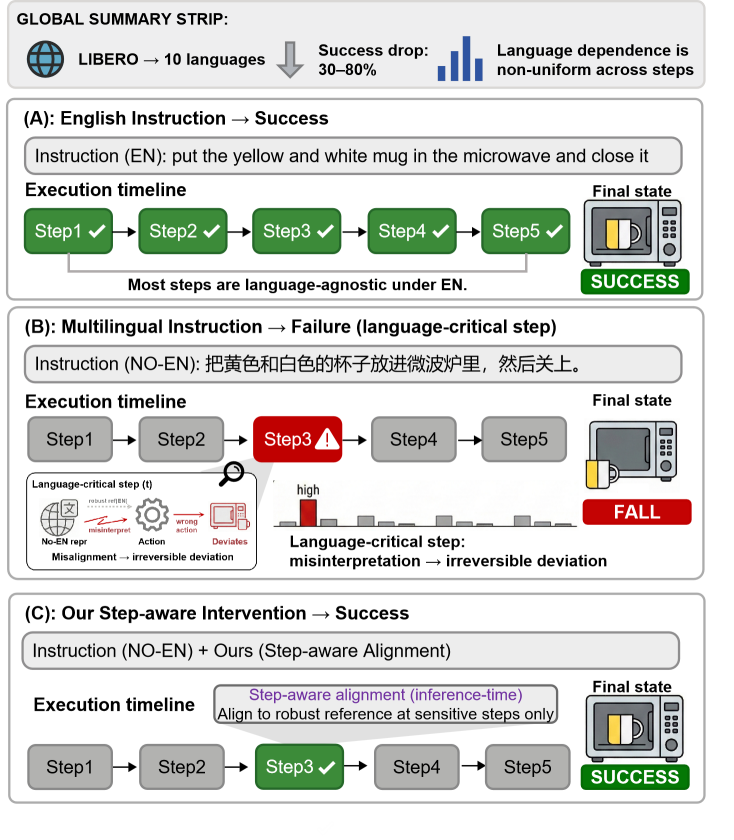
⚡ When Does Language Matter? Multilingual Instructions Reveal Step-wise Language Grounding in VLA
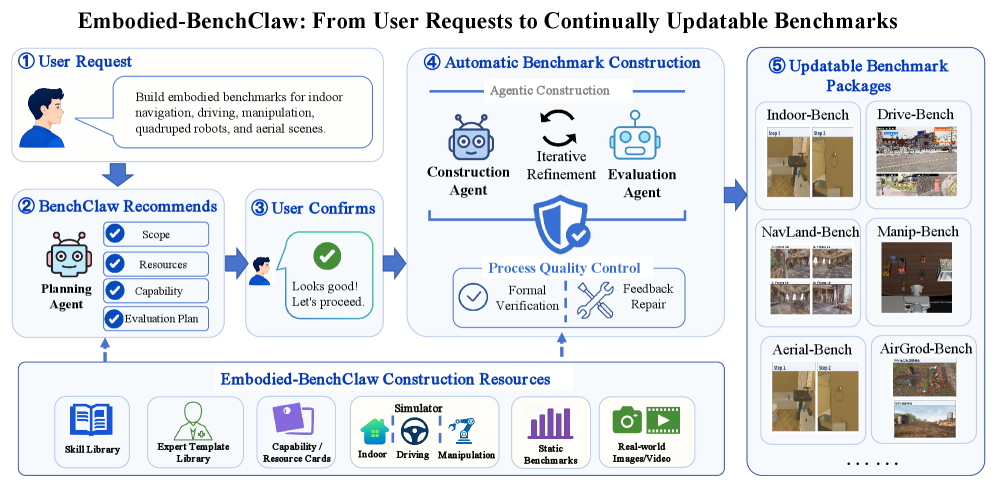
⚡ Embodied-BenchClaw: An Autonomous Multi-Agent System for Embodied Spatial Intelligence
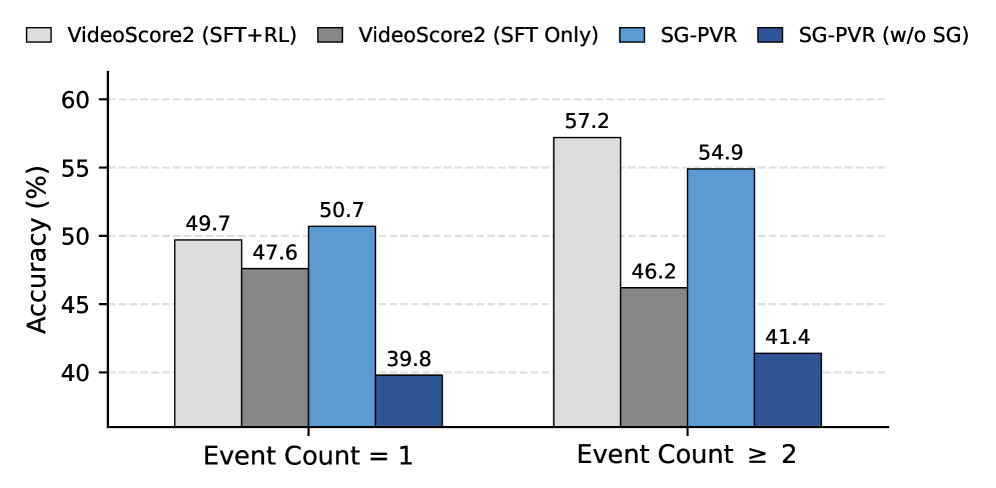
⚡ Plan-and-Verify Video Reward Reasoning with Spatio-Temporal Scene Graph Grounding
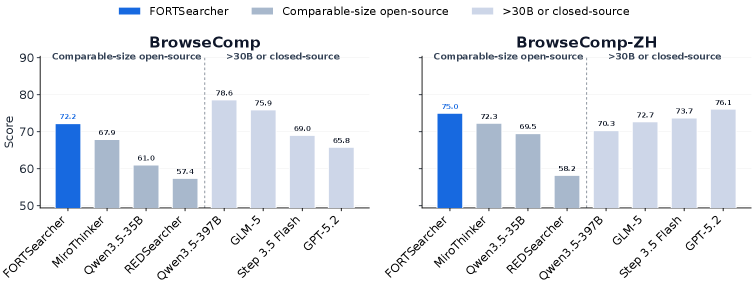
⚡ FORT-Searcher: Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents
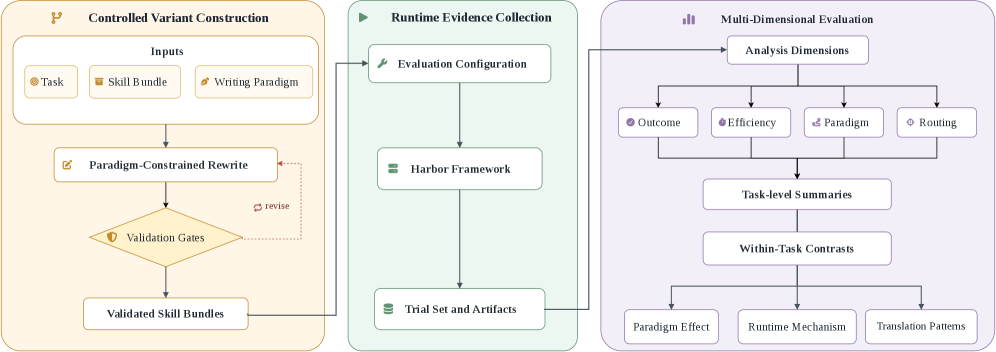
⚡ SkillJuror: Measuring How Agent Skill Organization Changes Runtime Behavior
⚡ Beyond Compaction: Structured Context Eviction for Long-Horizon Agents
自动生成于 2026-06-12 · 基于 arXiv Daily Digest